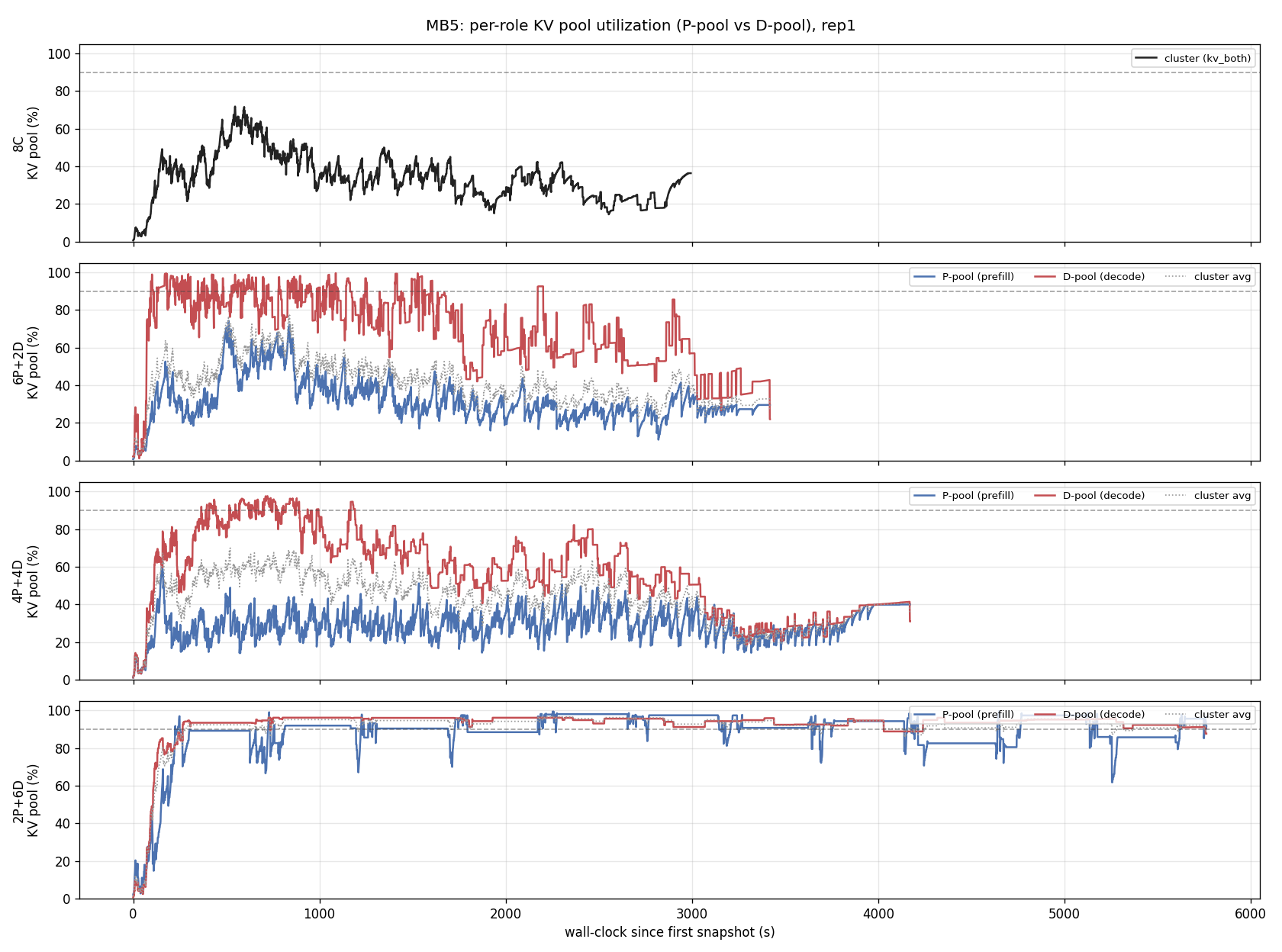
aggregate_mb5.py: - Split the cluster KV timeline by role (P-pool vs D-pool) using a PID->role map parsed from vllm_logs filenames. The cluster average hid the result — 6P+2D/4P+4D look ~45% utilized but the decode pool is actually pegged at ~100% while prefill idles at ~30%. - Two-stage reduce/plot: --reduce-to (numpy-only, runs on the serving host over multi-GB snapshot dirs) dumps a compact JSON; --from-reduced (matplotlib) renders locally. matplotlib import is now lazy. - New plot_role_split figure + p/d peak/steady columns in the CSV. PD_DISAGG_RESULTS.md: consolidated writeup with figures inline. Verdict: no static P:D ratio beats 8C colocation. The binding constraint moves with the ratio (D-pool saturates at 6P+2D/4P+4D, P-pool jams at 2P+6D -> 91% request loss); 8C's shared pool stays elastic at 34% steady, 100% completion. PD wins TPOT (10-35x cleaner, the MB1 phase-isolation benefit is real) but loses TTFT and sheds load. Round-robin P routing also zeroes prefix-cache reuse; a session-affinity re-run of 6P+2D is in flight to test the fix. Figures (rep1): mb5_kv_timeline, mb5_role_split, mb5_peak_utilization, mb5_latency_compare + mb5_summary.csv. Co-Authored-By: Claude Opus 4.7 <noreply@anthropic.com>
375 KiB
1680x1248px
375 KiB
1680x1248px
{kind=link}
{kind=link}