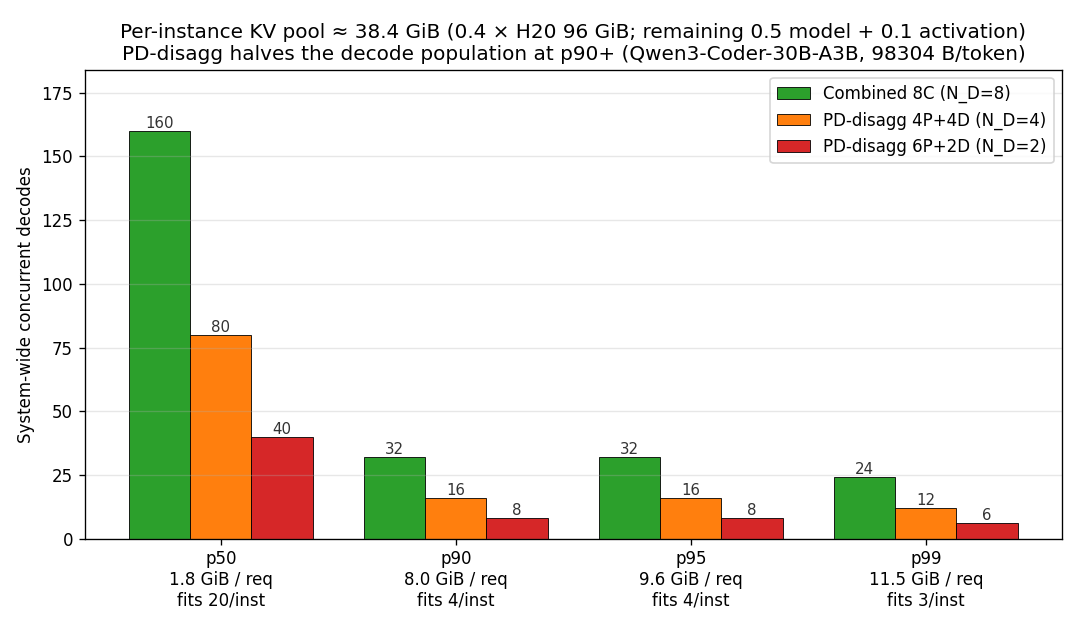
Old f2c plotted per-request KV footprint MiB against an "H20 ~95 GiB usable" reference line. That ceiling was wrong — a 30B-A3B bf16 deployment burns roughly: ~50% HBM for model params (~48 GiB on 96 GiB H20) ~10% for runtime activation buffers ~40% left for the KV cache pool (~38.4 GiB) so 95 GiB was overstating the available pool by 2.5×. New f2c reframes the same data into the answer that actually motivates the paper: how many concurrent decodes does a single instance hold, and how does PD-disagg change that? Grouped bars per percentile show system-wide concurrent decode capacity for three 8-GPU deployments: Combined 8C, PD-disagg 4P+4D (N_D=4), PD-disagg 6P+2D (N_D=2) Key reads off the figure: p50 (1.8 GiB/req): 20 fit/inst → 160 / 80 / 40 system-wide p90 (8.0 GiB/req): 4 fit/inst → 32 / 16 / 8 p95 (9.6 GiB/req): 4 fit/inst → 32 / 16 / 8 p99 (11.5 GiB/req): 3 fit/inst → 24 / 12 / 6 PD-disagg 4P+4D literally halves the decode population at the same per-request KV pressure — this is the concrete §3.2 "KV memory wall" penalty stated in terms users care about (concurrency). - analysis/characterization/render_window1_figures.py: fig_kv_footprint_cdf rewritten; reads same kv_footprint_summary.json but computes floor(KV_pool / req_size) × N_D and annotates the per-instance fit count below each percentile group. - figs/f2c_kv_footprint_cdf.png: regenerated. - MEETING.md / PAPER_OUTLINE.md §2.1, §2.4: prose updated with the new ceiling and the "3 p99 decodes per instance / halved by PD-disagg" framing. Co-Authored-By: Claude Opus 4.7 <noreply@anthropic.com>
73 KiB
1080x624px
73 KiB
1080x624px
{kind=link}
{kind=link}