Full sweep result on dash1 GPU 0+1 with vanilla vLLM 0.18.1 +
mooncake-transfer-engine 0.3.11, kv_both connector. Per-stage decomposition
via the instrumentation patch (analyze_mb2.py pairs A's send_blocks with
B's receive_kv enter/finish by time window).
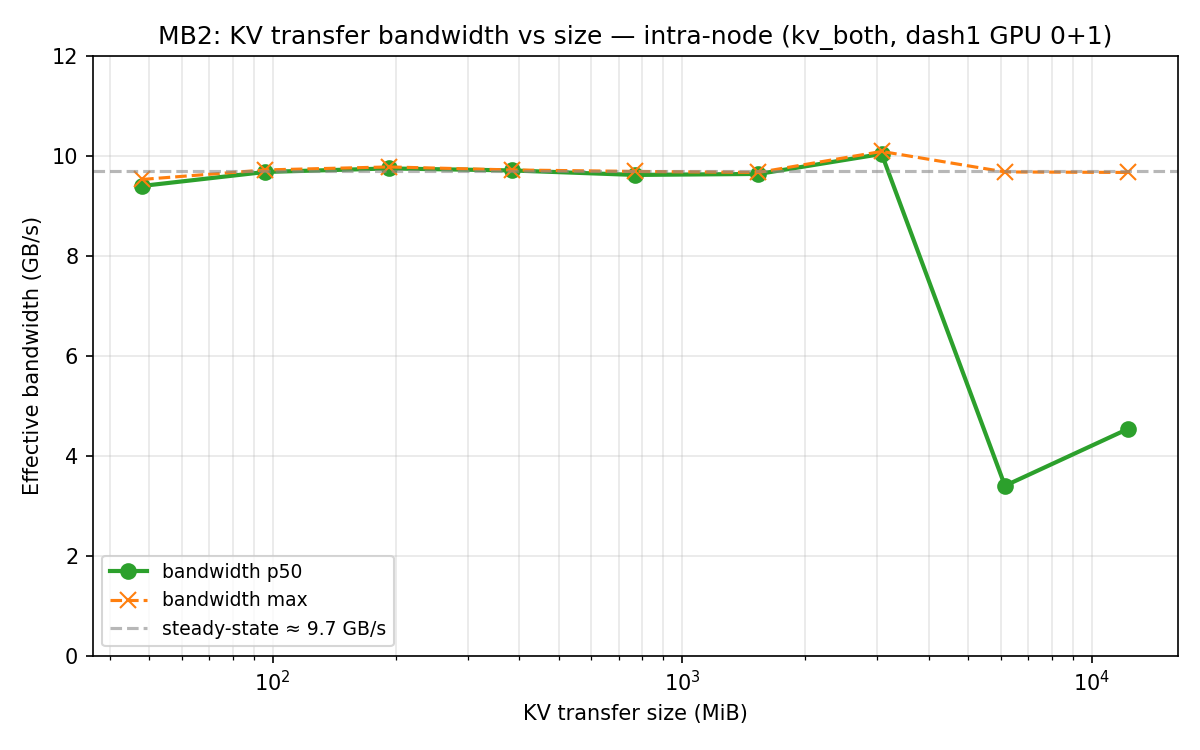
Steady-state (1k..32k tokens, 96 MiB..3 GiB KV):
pure_transfer ≈ size / 9.7 GB/s
rx_overhead ≈ 2–3 ms (ZMQ handshake + P-side setup)
bandwidth ≈ 9.6–10.1 GB/s, very stable
Large-size regime (65k..131k tokens, 6..12 GiB):
p50 bandwidth collapses to 3.4–4.5 GB/s
max bandwidth still hits ~9.7 GB/s (some runs achieve it)
p99 agentic request (11.5 GiB) lands here
Implication for §3.2 PD-disaggregation cost argument:
median agentic decode = 50–200 ms (tool-call JSON output)
median agentic-tail KV transfer (p99 11.5 GiB):
best case (9.7 GB/s) ≈ 1.19 s
observed range 1.5 – 10 s
⇒ KV transfer is 8–100× larger than the decode it enables.
This is intra-node — the lower-bound transfer cost. Inter-node RDMA
will be slower; that's MB2 phase 2.
Adds:
- analyze_mb2.py: pair A.send_blocks ↔ B.receive_kv by time window;
per-size aggregation (n, ms_p50, ms_min/max, GB/s_p50/max)
- plot_mb2.py: log-log transfer-time chart + bandwidth-vs-size chart
- analysis/mb2/A_intra_kvboth.jsonl, B_intra_kvboth.jsonl: raw events
(51 + 102 events including the sanity preamble)
- analysis/mb2/intra_kvboth_breakdown.json: paired and aggregated
- figs/mb2_transfer_time_intra.png, figs/mb2_transfer_bw_intra.png
Co-Authored-By: Claude Opus 4.7 <noreply@anthropic.com>
72 KiB
1200x750px
72 KiB
1200x750px
{kind=link}
{kind=link}