Three-axis controlled ablation of PD-colo vs PD-disagg on synthetic regular
traces (closed-loop, controlled reuse via REPLAY_NO_REALIZED_PREFIX) on the
clean stack (e13391e gated off).
Axis 1 (Fig 1) -- reuse 6%->94% at N=8, in8192/out256
Axis 2 (Fig 2) -- shape in2048/out2048 -> in32768/out64 at N=8, reuse~70%
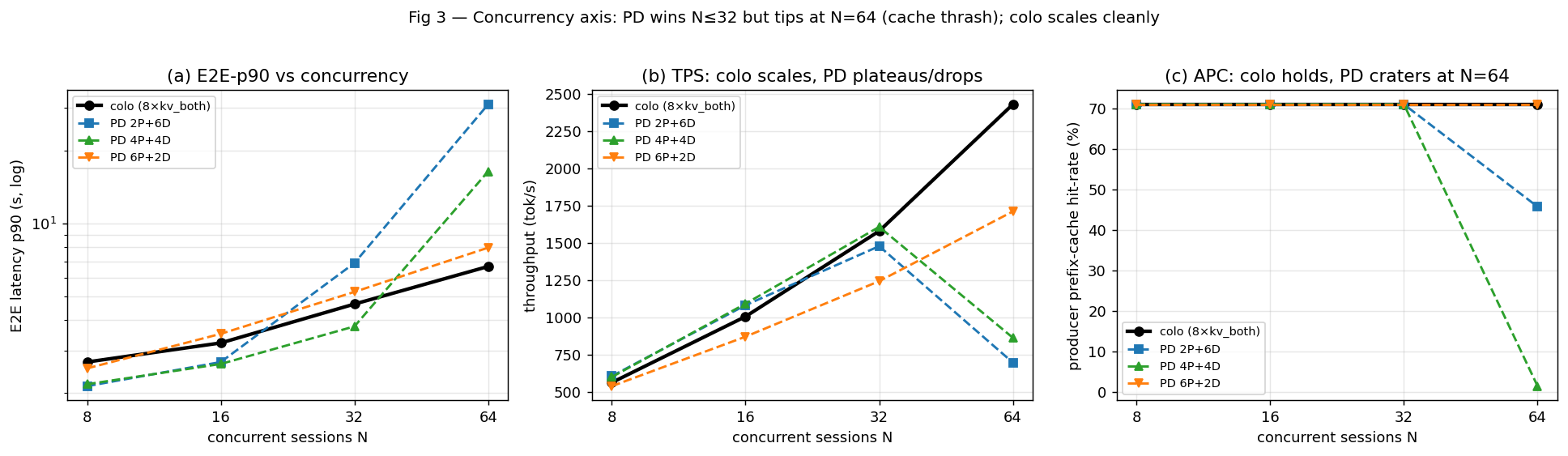
Axis 3 (Fig 3) -- concurrency N=8/16/32/64 at reuse~71%, in8192/out256
Findings:
* APC parity colo=PD at every reuse (5.5/22/44/66/77/82%) -- contamination
fix validated.
* PD edge erodes 1.57x->1.10x with reuse; prefill GPUs strand 26%->9%.
* Shape: PD-best peaks mid-sweep (1.34x at in8192/out512); wrong PD ratio
catastrophic at prefill extreme (in32768/out64 pd2 = 378/400, p99 432s).
* Concurrency: PD wins N<=32 (1.23-1.29x), TIPS at N=64 -- pd2/pd4
crater (APC 71%->1.4%, TPS -30%) while colo scales cleanly.
Infrastructure:
* replayer: --max-inflight-sessions, --inter-turn-think, --no-realized-prefix
(env-defaulted via REPLAY_MAX_INFLIGHT, REPLAY_INTER_TURN_THINK_S,
REPLAY_NO_REALIZED_PREFIX).
* mb5_run.sh: writes bench_config.json + gpu_util.csv + run_window.json +
instance_apc.txt + metrics.jsonl for bench_report/fig_agg ingest.
* fig_agg.py: per-arm GPU role split + producer-side APC; --json mode.
* gpu_util_report.py: companion per-GPU util report from gpu_util.csv.
* partial_summary.py: stats from in-flight replay_metrics.jsonl
(works before metrics.summary.json exists).
Data: analysis/mb5_pd_ablation/fig{1,2,3}.json (24 + 20 + 16 rows).
Figures: figs/mb5_pd_ablation/fig{1_reuse,2_shape,3_concurrency}_axis.png.
158 KiB
1936x563px
158 KiB
1936x563px
{kind=link}
{kind=link}